

SageMath เป็นซอฟต์แวร์โอเพ่นซอร์สที่ใช้สำหรับการคำนวณทางคณิตศาสตร์ ที่สามารถดาวน์โหลดและใช้งานได้ฟรี ซึ่งหมายความว่าไม่ต้องเสียค่าใช้จ่ายในการใช้งาน และผู้ใช้สามารถเข้าถึงและแก้ไขโค้ดได้ตามต้องการ มันรวมฟังก์ชันจากหลายโปรแกรมคอมพิวเตอร์ที่มีชื่อเสียง เช่น MATLAB, Maple, Mathematica, และ R โดยมีจุดมุ่งหมายเพื่อให้ผู้ใช้สามารถทำการคำนวณทางคณิตศาสตร์ได้อย่างครบถ้วนและมีประสิทธิภาพ SageMath ใช้ภาษา Python เป็นหลักในการเขียนโค้ด ซึ่งเป็นภาษาโปรแกรมที่ได้รับความนิยมและง่ายต่อการเรียนรู้ โดยมีคุณสมบัติสำคัญคือ
- การคำนวณพีชคณิตและการแก้สมการ
- การวิเคราะห์เชิงตัวเลขและสถิติ
- การสร้างกราฟและการวิเคราะห์ทางเรขาคณิต
- การจัดการกับโครงสร้างทางคณิตศาสตร์ที่ซับซ้อน เช่น พื้นที่เวกเตอร์, แมทริกซ์, และวงแหวน
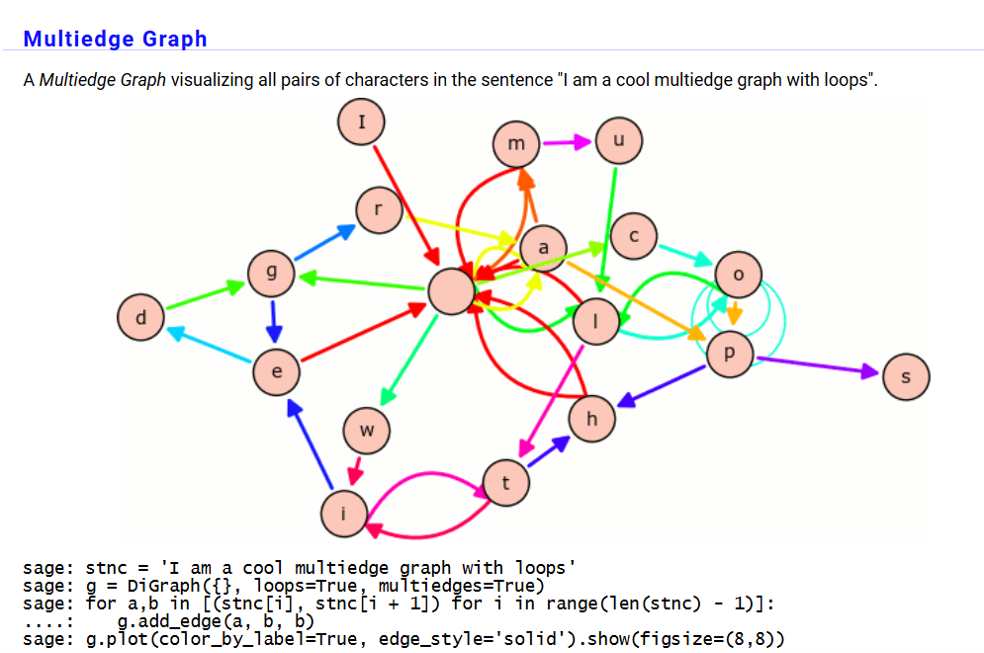
การใช้ SageMath สามารถทำได้ผ่านทางกราฟิก (SageMath Notebook) หรือผ่านทางใช้คำสั่ง (SageMath Command Line) นอกจากนี้ยังมีเวอร์ชันที่สามารถใช้ผ่านเว็บเบราว์เซอร์ที่เรียกว่า SageMathCloud หรือ CoCalc ซึ่งช่วยให้ผู้ใช้สามารถทำงานร่วมกันและเข้าถึงเครื่องมือทางคณิตศาสตร์ได้จากทุกที่

DevOps เป็นแนวคิดการผสมผสานระหว่าง การพัฒนาซอฟต์แวร์ (Development) และ การดำเนินงานด้าน IT Operations โดยมุ่งเน้นการสร้างกระบวนการทำงานที่ช่วยให้ทีมพัฒนาซอฟต์แวร์และทีมปฏิบัติการทำงานร่วมกันได้อย่างใกล้ชิดมากขึ้น มีจุดมุ่งหมายเพื่อลดช่องว่างระหว่างการพัฒนาและการนำซอฟต์แวร์ไปใช้งานจริง และช่วยเพิ่มประสิทธิภาพการส่งมอบซอฟต์แวร์ที่รวดเร็วและมีคุณภาพ
ตัวอย่างของกระบวนการ DevOps มีดังนี้:
- Planning
- ทีมพัฒนาซอฟต์แวร์และทีมปฏิบัติการทำงานร่วมกันเพื่อกำหนดความต้องการทางธุรกิจ กำหนดคุณสมบัติของซอฟต์แวร์ และวางแผนการพัฒนา โดยใช้เครื่องมือช่วยในการจัดการโปรเจกต์ เช่น Jira, Trello หรือ Azure DevOps
- Development
- นักพัฒนาเขียนโค้ดและพัฒนาฟีเจอร์ของแอปพลิเคชัน โดยใช้ระบบควบคุมเวอร์ชัน (Version Control) เช่น Git เพื่อเก็บรักษาและจัดการโค้ด
- เครื่องมือที่ใช้: Git, GitHub, GitLab
- Testing
- โค้ดที่เขียนจะต้องผ่านการทดสอบโดยอัตโนมัติ Automated Testing เพื่อตรวจสอบความถูกต้อง เช่น การทดสอบหน่วย (Unit Testing) และการทดสอบบูรณาการ (Integration Testing) ตัวอย่างของกระบวนการ DevOps:
- เครื่องมือที่ใช้: Selenium, JUnit, TestNG
- Integration & Build
- กระบวนการรวมโค้ดจากนักพัฒนาหลายๆ คนและสร้างระบบซอฟต์แวร์โดยอัตโนมัติ เพื่อให้แน่ใจว่าโค้ดสามารถทำงานร่วมกันได้ Continuous Integration (CI)
- เครื่องมือที่ใช้: Jenkins, CircleCI, Travis CI
- Infrastructure as Code
- การจัดการโครงสร้างพื้นฐานเช่นเซิร์ฟเวอร์หรือเครือข่ายจะถูกควบคุมด้วยโค้ด ทำให้สามารถปรับเปลี่ยนหรือเพิ่มขยายได้ง่ายและมีประสิทธิภาพ
- เครื่องมือที่ใช้: Terraform, Ansible, Chef, Puppet
- Deployment
- เมื่อนำซอฟต์แวร์ผ่านการทดสอบและพร้อมใช้งาน กระบวนการ Deploy จะถูกทำโดยอัตโนมัติไปยังสภาพแวดล้อมต่างๆ เช่น Dev, Test, Production
- เครื่องมือที่ใช้: Docker, Kubernetes
- Monitoring & Logging
- ซอฟต์แวร์ที่ใช้งานแล้วจะถูกตรวจสอบเพื่อติดตามสถานะและประสิทธิภาพการทำงาน หากมีปัญหาเกิดขึ้นจะสามารถแก้ไขได้อย่างรวดเร็ว
- เครื่องมือที่ใช้: Prometheus, Grafana, ELK Stack (Elasticsearch, Logstash, Kibana)
- Continuous Feedback & Improvement
- เมื่อซอฟต์แวร์ถูกนำไปใช้งานแล้ว ต้องรวบรวมข้อมูลจากผู้ใช้งานและระบบเพื่อปรับปรุงซอฟต์แวร์อย่างต่อเนื่อง กระบวนการนี้เป็นการทำให้การพัฒนาและการนำไปใช้งานมีการหมุนเวียนอย่างสม่ำเสมอ
ประโยชน์ของ DevOps
- การส่งมอบซอฟต์แวร์ที่รวดเร็วขึ้น (Faster Delivery) : DevOps ช่วยลดเวลาในการพัฒนาซอฟต์แวร์ตั้งแต่การเขียนโค้ดไปจนถึงการส่งมอบหรือ deploy ซอฟต์แวร์ เพราะมีการทำงานร่วมกันระหว่างทีมพัฒนาและทีมปฏิบัติการอย่างใกล้ชิด รวมถึงการใช้เครื่องมืออัตโนมัติในการทดสอบและ deploy ทำให้สามารถออกฟีเจอร์ใหม่ ๆ หรือการแก้ไขบั๊กได้อย่างรวดเร็ว
- การปรับปรุงคุณภาพของซอฟต์แวร์ (Improved Quality) : กระบวนการทดสอบอัตโนมัติ (Automated Testing) ทำให้สามารถตรวจพบข้อผิดพลาดได้เร็วกว่า ซึ่งช่วยลดปัญหาที่อาจเกิดขึ้นในภายหลัง และการตรวจสอบประสิทธิภาพของระบบหลังการ deploy อย่างสม่ำเสมอช่วยลดการหยุดทำงานของระบบและปรับปรุงคุณภาพอย่างต่อเนื่อง
- การปรับปรุงความเสถียรของระบบ (Increased System Stability) : ด้วยการใช้เครื่องมือและการตั้งค่าโครงสร้างพื้นฐานเป็นโค้ด (Infrastructure as Code – IaC) DevOps ทำให้ระบบสามารถรองรับการเปลี่ยนแปลงได้โดยมีความเสี่ยงน้อยลง ลดข้อผิดพลาดที่เกิดจากการเปลี่ยนแปลงการตั้งค่าที่ไม่เหมาะสม ทำให้ระบบที่ใช้งานจริงจะมีความเสถียรและมั่นคงมากขึ้น
- เพิ่มความสามารถในการทำงานร่วมกัน (Improved Collaboration) : DevOps ช่วยให้ทีมพัฒนาและทีมปฏิบัติการทำงานร่วมกันได้อย่างราบรื่น เนื่องจากมีการรวมเครื่องมือและกระบวนการที่เชื่อมโยงกัน ลดช่องว่างการสื่อสารและความขัดแย้งระหว่างทีม
- การตอบสนองที่รวดเร็วต่อการเปลี่ยนแปลง (Faster Recovery and Adaptation) : หากเกิดปัญหาขึ้นในระบบ ทีมสามารถตอบสนองและแก้ไขปัญหาได้อย่างรวดเร็ว ด้วยการใช้เครื่องมืออัตโนมัติและการตรวจสอบอย่างต่อเนื่อง นอกจากนี้ยังทำให้สามารถปรับเปลี่ยนหรือขยายระบบได้ทันทีตามความต้องการของธุรกิจ
- การเพิ่มประสิทธิภาพของทรัพยากร (Resource Optimization) : DevOps ช่วยให้การจัดการทรัพยากร เช่น เซิร์ฟเวอร์หรือโครงสร้างพื้นฐานมีประสิทธิภาพมากขึ้นโดยการใช้เทคโนโลยีคลาวด์และการจัดการโครงสร้างพื้นฐานด้วยโค้ด (IaC) ทำให้สามารถปรับขนาดระบบให้สอดคล้องกับความต้องการได้อย่างเหมาะสม
- การปรับปรุงนวัตกรรม (Fostering Innovation) : ด้วยการส่งมอบซอฟต์แวร์ที่เร็วและการทดสอบที่ง่ายขึ้น นักพัฒนาสามารถมุ่งเน้นไปที่การสร้างฟีเจอร์ใหม่ๆ และนวัตกรรมที่ตอบโจทย์ตลาดได้มากขึ้น
- การลดต้นทุน (Cost Efficiency) : ด้วยกระบวนการอัตโนมัติและการทำงานร่วมกันที่มีประสิทธิภาพ DevOps ช่วยลดต้นทุนทั้งในด้านแรงงานและทรัพยากร เช่น การลดเวลาในการ deploy ซอฟต์แวร์ การลดข้อผิดพลาดที่เกิดขึ้นในขั้นตอนต่างๆ รวมถึงการลดเวลาหยุดทำงานของระบบ (downtime)
โดยสรุปแล้ว DevOps ช่วยเพิ่มความคล่องตัว ความแม่นยำ และคุณภาพของการพัฒนาซอฟต์แวร์อย่างมาก ซึ่งนำไปสู่ประสิทธิภาพที่สูงขึ้นในองค์กรและความพึงพอใจที่เพิ่มขึ้นของลูกค้า
PaLM 2 (Pathways Language Model 2) เป็นโมเดลภาษาขนาดใหญ่ (LLM) ที่พัฒนาโดย Google รายละเอียดเพิ่มเติมอยู่ที่ https://ai.google/discover/palm2 เปิดตัวในปี 2023 เป็นเวอร์ชันที่ปรับปรุงขึ้นจาก PaLM รุ่นแรก โดยเพิ่มขีดความสามารถในการประมวลผลภาษาธรรมชาติได้หลากหลายภาษา รวมถึงพัฒนาความสามารถในการทำงานเฉพาะด้าน
ความแตกต่างระหว่าง PaLM 2 กับ LLM อื่น ๆ:
- สถาปัตยกรรมและประสิทธิภาพ:
- PaLM 2 สร้างขึ้นโดยใช้สถาปัตยกรรม Pathways ของ Google ซึ่งช่วยให้สามารถประมวลผลข้อมูลหลายชุดพร้อมกันได้อย่างมีประสิทธิภาพและยืดหยุ่น โดยสามารถใช้งานโมเดลเดียวกับงานที่แตกต่างกันได้หลายประเภท
- ในขณะที่ LLM ทั่วไป เช่น GPT อาจเน้นไปที่การสร้างภาษาและการตอบคำถามโดยใช้ความเข้าใจเชิงบริบท PaLM 2 มีการออกแบบมาเพื่อรองรับการใช้งานที่หลากหลายและซับซ้อนขึ้น เช่น การทำงานด้านคณิตศาสตร์และวิทยาศาสตร์
- ความสามารถในหลายภาษา:
- PaLM 2 ถูกฝึกด้วยข้อมูลหลายภาษา ทำให้สามารถทำงานกับภาษาต่าง ๆ ได้ดีกว่า LLM ทั่วไป
- มีความสามารถในการจัดการกับไวยากรณ์ วากยสัมพันธ์ และคำศัพท์ที่ซับซ้อนได้แม่นยำมากขึ้น
- การปรับปรุงเฉพาะด้าน:
- PaLM 2 ได้รับการฝึกอบรมเพิ่มเติมในสาขาเฉพาะ เช่น การเขียนโปรแกรม การวิเคราะห์ทางชีวภาพ และการทำงานด้านการรักษาความปลอดภัยของข้อมูล
- ในขณะที่ LLM อื่น ๆ มักเน้นการประมวลผลภาษาธรรมชาติทั่วไป
- การใช้งานเชิงพาณิชย์และวิจัย:
- PaLM 2 ได้รับการปรับแต่งสำหรับการใช้งานที่ต้องการความแม่นยำสูง เช่น งานวิทยาศาสตร์ เทคโนโลยี และการแพทย์
- LLM ทั่วไปมักจะใช้ในการสร้างเนื้อหา การตอบคำถาม และการทำงานภาษาที่กว้างขวางมากกว่า
นอกจากนี้ทาง Google ได้พัฒนาบริการ PaLM API เป็น API ที่ Google พัฒนาขึ้นเพื่อให้ผู้พัฒนาสามารถเข้าถึงโมเดลภาษาขนาดใหญ่ (LLM) ของ PaLM 2 ได้ง่ายขึ้น โดย API นี้ช่วยให้นักพัฒนาสามารถสร้างแอปพลิเคชันที่ใช้ความสามารถของปัญญาประดิษฐ์ (AI) ในการประมวลผลภาษาธรรมชาติ การตอบคำถาม และการทำงานอื่น ๆ ที่เกี่ยวข้องกับการสร้างและจัดการข้อความ ตัวอย่างเช่น การสร้างแชทบอท การตอบคำถามโดยใช้ฐานข้อมูลขนาดใหญ่ หรือการสร้างคอนเทนต์อัตโนมัติ ช่วยในการสรุปเนื้อหา การแปลภาษา หรือการดึงข้อมูลจากข้อความและช่วยให้นักพัฒนาสร้างโซลูชัน AI ที่เกี่ยวกับการสร้างเนื้อหา การจัดการข้อมูล และการวิเคราะห์ข้อมูลในภาษาต่าง ๆ

Data Visualization เป็นกระบวนการแปลงข้อมูลที่เป็นตัวเลขหรือข้อมูลที่มีลักษณะเป็นข้อความจำนวนมากให้อยู่ในรูปแบบภาพ เช่น แผนภูมิ กราฟ หรือแผนที่ เพื่อช่วยในการทำความเข้าใจและสื่อสารข้อมูลนั้นๆ ได้ง่ายและมีประสิทธิภาพมากขึ้น การแสดงผลข้อมูลด้วยภาพทำให้ผู้ชมสามารถรับรู้แนวโน้ม รูปแบบ หรือความสัมพันธ์ของข้อมูลได้รวดเร็วและง่ายดาย Data Visualization มีหลายประเภทของกราฟและแผนภูมิที่สามารถใช้ได้ ขึ้นอยู่กับลักษณะของข้อมูลที่ต้องการแสดงผล โดยทั่วไปสามารถแบ่งตามประเภทของข้อมูลได้ดังนี้:
ข้อมูลเชิงเปรียบเทียบ (Comparison)
- กราฟแท่ง (Bar Chart): ใช้สำหรับเปรียบเทียบค่าของข้อมูลในกลุ่มต่างๆ เช่น ยอดขายรายเดือน
- กราฟเส้น (Line Chart): ใช้สำหรับแสดงแนวโน้มของข้อมูลตลอดช่วงเวลาหนึ่งๆ เช่น การเปลี่ยนแปลงของราคาหุ้น
- กราฟแท่งซ้อน (Stacked Bar Chart): แสดงการเปรียบเทียบและการแบ่งส่วนภายในกลุ่มเดียวกัน
ข้อมูลเชิงสัดส่วน (Proportion)
- กราฟวงกลม (Pie Chart): แสดงสัดส่วนของส่วนประกอบภายในกลุ่มทั้งหมด เช่น ส่วนแบ่งตลาดของแต่ละบริษัท
- กราฟโดนัท (Donut Chart): คล้ายกับกราฟวงกลมแต่มีช่องว่างตรงกลาง ทำให้สามารถใส่ข้อมูลเพิ่มเติมได้
- Tree Map: แสดงข้อมูลเป็นส่วนประกอบของกลุ่มที่ใหญ่กว่า เช่น สัดส่วนพื้นที่ในงบประมาณของแต่ละแผนก
ข้อมูลเชิงกระจาย (Distribution)
- กราฟฮิสโตแกรม (Histogram): ใช้แสดงการกระจายของข้อมูลที่เป็นค่าต่อเนื่อง เช่น การกระจายของคะแนนสอบ
- กราฟจุด (Dot Plot): ใช้แสดงการกระจายตัวของข้อมูลแต่ละจุดในกลุ่มข้อมูล
- กราฟกล่อง (Box Plot): แสดงการกระจายของข้อมูลและจุดที่เป็น outlier
ข้อมูลเชิงความสัมพันธ์ (Relationship)
- กราฟกระจาย (Scatter Plot): แสดงความสัมพันธ์ระหว่างตัวแปรสองตัว เช่น ความสัมพันธ์ระหว่างอายุและรายได้
- Bubble Chart: เป็นการต่อยอดจากกราฟกระจายโดยการเพิ่มขนาดของฟองเพื่อแสดงตัวแปรที่สาม
- Heatmap: ใช้แสดงความสัมพันธ์ของข้อมูลหลายมิติ โดยใช้สีเพื่อแสดงระดับความเข้มของค่า
ข้อมูลเชิงลำดับขั้น (Hierarchical Data)
- Tree Diagram: แสดงข้อมูลเป็นลำดับขั้นจากระดับสูงไปยังระดับต่ำ
- Sunburst Chart: คล้ายกับ Tree Diagram แต่แสดงเป็นวงกลมหลายชั้น
ข้อมูลที่เป็นแผนที่ (Geospatial Data)
- Choropleth Map: ใช้แสดงข้อมูลตามภูมิศาสตร์ โดยใช้สีเพื่อแสดงความเข้มข้นของข้อมูลในพื้นที่ต่างๆ
- Dot Density Map: แสดงการกระจายของข้อมูลในพื้นที่หนึ่งๆ โดยใช้จุดแทนข้อมูลแต่ละจุด
การเลือกใช้กราฟหรือแผนภูมิที่เหมาะสมกับข้อมูลเป็นสิ่งสำคัญ เพื่อให้การสื่อสารข้อมูลนั้นๆ มีประสิทธิภาพและชัดเจนมากที่สุด ปัจจุบันมีเครื่องมือ Data Visualization ที่หลากหลายทั้งที่เป็นแบบฟรีและมีค่าใช้จ่าย ซึ่งสามารถเลือกใช้งานตามความต้องการและความสามารถของเครื่องมือแต่ละตัว ดังนี้:
เครื่องมือ Data Visualization แบบใช้ได้ฟรี
- Google Data Studio
-
- ใช้งานฟรีสำหรับการสร้างรายงานและแดชบอร์ด สามารถเชื่อมต่อกับ Google Sheets, Google Analytics, และแหล่งข้อมูลอื่นๆ
- Tableau Public
- รุ่นฟรีของ Tableau ที่ให้คุณสร้างและแบ่งปัน Visualizations ออนไลน์ แต่ไม่สามารถเก็บไฟล์ข้อมูลในเครื่องได้ ข้อมูลทั้งหมดจะต้องเผยแพร่ในพื้นที่สาธารณะ
- Microsoft Power BI Desktop
- รุ่นฟรีของ Power BI ที่มีความสามารถในการสร้างรายงานและแดชบอร์ด แต่มีข้อจำกัดในส่วนของการแชร์และการทำงานร่วมกัน ซึ่งมีค่าใช้จ่ายเพิ่มเติมในเวอร์ชันเต็ม
- Plotly
- แพลตฟอร์มโอเพนซอร์สที่ช่วยสร้างกราฟเชิงโต้ตอบได้ทั้งใน Python, R, และ JavaScript สามารถใช้งานฟรีได้ในระดับพื้นฐาน
- D3.js
- ไลบรารี JavaScript แบบโอเพนซอร์สที่ทรงพลังสำหรับการสร้าง Data Visualizations ที่ปรับแต่งได้อย่างสมบูรณ์ แม้จะต้องใช้ความรู้ด้านการเขียนโปรแกรม
- Chart.js
- ไลบรารี JavaScript แบบโอเพนซอร์สที่เหมาะสำหรับการสร้างกราฟพื้นฐาน เช่น กราฟแท่ง กราฟเส้น กราฟวงกลม เป็นต้น
เครื่องมือ Data Visualization ที่มีค่าใช้จ่าย
- Tableau
- เครื่องมือที่มีประสิทธิภาพสูงสำหรับการสร้าง Visualizations แบบมืออาชีพ รองรับการเชื่อมต่อกับแหล่งข้อมูลหลากหลาย สามารถสร้างแดชบอร์ดเชิงโต้ตอบได้ง่าย ใช้ได้ทั้งแบบ Desktop, Online และ Server
- Microsoft Power BI Pro
- เป็นเวอร์ชันที่มีค่าใช้จ่ายของ Power BI ซึ่งเพิ่มความสามารถในการแชร์และทำงานร่วมกับทีม และการใช้งาน Power BI Service ในคลาวด์
- QlikView/Qlik Sense
- เครื่องมือ Data Visualization ที่เน้นการทำงานเชิงวิเคราะห์ด้วยความสามารถในการดึงข้อมูลจากแหล่งต่างๆ และสร้าง Visualizations ที่ซับซ้อนได้
- Looker (Google Cloud)
- แพลตฟอร์ม BI ที่เน้นการสร้างรายงานและแดชบอร์ดเชิงโต้ตอบที่มีการรวมการวิเคราะห์ข้อมูลแบบ Real-time
- SAP Analytics Cloud
- เครื่องมือ BI บนคลาวด์ที่มีความสามารถในการวิเคราะห์ข้อมูล, การสร้างรายงาน และการวางแผนที่ครอบคลุมทั้งในด้านการวิเคราะห์และการสื่อสารข้อมูล
- Sisense
- เครื่องมือ BI ที่มีความสามารถสูงในการรวมข้อมูลจากแหล่งต่างๆ และสร้าง Visualizations ที่ปรับแต่งได้ตามต้องการ
CRO (Conversion Rate Optimization) คือกระบวนการปรับปรุงและเพิ่มประสิทธิภาพของเว็บไซต์หรือหน้า Landing Page เพื่อเพิ่ม Conversion Rate) ซึ่งหมายถึงการเพิ่มจำนวนผู้เข้าชมที่ทำตามเป้าหมายที่คุณกำหนด เช่น การสมัครสมาชิก การซื้อสินค้า หรือการกรอกแบบฟอร์ม
หลักการสำคัญของ CRO:
- การทำความเข้าใจพฤติกรรมผู้ใช้: ใช้เครื่องมือเช่น Google Analytics, Heatmaps, หรือ Session Recordings เพื่อเข้าใจว่าผู้ใช้ทำอะไรบนเว็บไซต์ คุณสามารถดูว่าเขาคลิกอะไร ติดขัดตรงไหน หรือทำไมถึงออกจากเว็บไซต์
- การทดสอบ A/B Testing: การทดลองเปรียบเทียบระหว่างสองเวอร์ชันของหน้าเว็บเพื่อดูว่าเวอร์ชันใดทำงานได้ดีกว่า เช่น การเปลี่ยนแปลงสีของปุ่ม การใช้ข้อความที่แตกต่าง หรือการปรับตำแหน่งขององค์ประกอบ
- การปรับปรุง UX/UI: การทำให้ประสบการณ์ของผู้ใช้ราบรื่นและมีความสุขจะช่วยเพิ่มอัตราการแปลง เช่น การลดจำนวนขั้นตอนในการกรอกแบบฟอร์ม การเพิ่มความเร็วในการโหลดหน้าเว็บ หรือการปรับหน้าเว็บให้เหมาะกับอุปกรณ์พกพา
- การทำ Content Optimization: การปรับปรุงเนื้อหาให้ตรงกับความต้องการของผู้ใช้และมีความน่าสนใจ เช่น การใช้ข้อความที่กระชับและชัดเจน การใช้ภาพที่ดึงดูด หรือการนำเสนอข้อเสนอที่มีคุณค่า
- การใช้ Social Proof และ Trust Signals: การเพิ่มรีวิวจากลูกค้า การใช้คำแนะนำจากผู้เชี่ยวชาญ หรือการแสดงโลโก้ของลูกค้าที่เคยใช้บริการ เป็นสิ่งที่ช่วยเพิ่มความเชื่อมั่นให้กับผู้ใช้ใหม่
- การวัดผลและการวิเคราะห์: หลังจากทำการปรับปรุงแล้ว คุณต้องติดตามและวัดผลว่าอัตราการแปลงเพิ่มขึ้นหรือไม่ และใช้ข้อมูลนี้ในการทำการตัดสินใจเพื่อปรับปรุงเพิ่มเติม
CRO เป็นกระบวนการที่ต่อเนื่องและควรทำเป็นประจำเพื่อให้เว็บไซต์หรือแคมเปญของคุณมีประสิทธิภาพสูงสุด ต้องอาศัยข้อมูลหลายประเภทเพื่อวิเคราะห์และปรับปรุงประสิทธิภาพของเว็บไซต์ ตัวอย่างของข้อมูลและเครื่องมือที่ใช้ใน CRO มีดังนี้:
ข้อมูลที่ใช้ใน CRO:
- พฤติกรรมผู้ใช้ (User Behavior)
- ข้อมูลเกี่ยวกับการคลิก การเลื่อนหน้า (scrolling) และการโต้ตอบกับหน้าเว็บ
- ข้อมูลจาก Heatmaps หรือ Session Recordings ที่แสดงว่าผู้ใช้โฟกัสที่ส่วนใดของหน้าเว็บ
- ข้อมูลเชิงประชากร (Demographics)
- อายุ เพศ ตำแหน่งที่อยู่ของผู้ใช้
- ข้อมูลที่เกี่ยวข้องกับอุปกรณ์ที่ใช้ (Desktop, Mobile, Tablet)
- ข้อมูลการนำทาง (Navigation Data)
- หน้าเว็บที่ผู้ใช้เยี่ยมชมก่อนทำการแปลง (Conversion Path)
- Bounce Rate หรืออัตราการออกจากหน้าเว็บ
- ข้อมูลทางเทคนิค (Technical Data)
- ความเร็วในการโหลดหน้าเว็บ (Page Load Time)
- ปัญหาทางเทคนิคที่อาจขัดขวางการแปลง เช่น ปุ่มที่ไม่สามารถคลิกได้
- ข้อมูลเชิงจิตวิทยา (Psychographics)
- แรงจูงใจ ความต้องการ และข้อกังวลของผู้ใช้
- ข้อมูลจากการสอบถามหรือแบบสำรวจ
เครื่องมือที่ช่วยในการทำ CRO:
- Google Analytics
- วิเคราะห์พฤติกรรมผู้ใช้ ดู Conversion Rate ของแต่ละหน้า และติดตามเส้นทางการแปลง
- Hotjar
- เครื่องมือ Heatmaps และ Session Recordings ที่ช่วยให้เห็นว่าผู้ใช้คลิกและเลื่อนหน้าอย่างไร รวมถึงการสอบถามผ่าน Polls และ Surveys
- Optimizely
- แพลตฟอร์มสำหรับ A/B Testing และการทดสอบหลายตัวแปร (Multivariate Testing) ช่วยในการทดลองและวิเคราะห์ผลลัพธ์
- Crazy Egg
- เครื่องมือ Heatmaps และการทดสอบ A/B ที่ช่วยในการวิเคราะห์และปรับปรุงหน้าเว็บ
- VWO (Visual Website Optimizer)
- แพลตฟอร์ม CRO ครบวงจรที่มี A/B Testing, Heatmaps, และการวิเคราะห์ Funnel
- Google Optimize
- เครื่องมือสำหรับทำ A/B Testing ที่เชื่อมต่อกับ Google Analytics เพื่อการวิเคราะห์ที่ลึกซึ้งขึ้น
- Mouseflow
- เครื่องมือสำหรับการบันทึกการโต้ตอบของผู้ใช้ (Session Recording) และการสร้าง Heatmaps รวมถึงการทำ Form Analytics
- Unbounce
- เครื่องมือสร้างและทดสอบหน้า Landing Page แบบไม่มีโค้ด พร้อมกับการทำ A/B Testing

SXO (Search Experience Optimization) เป็นแนวทางการพัฒนาและปรับปรุงเว็บไซต์ที่เน้นทั้งการทำ SEO เพื่อให้เว็บไซต์ติดอันดับในเครื่องมือค้นหา และประสบการณ์ของผู้ใช้ (User Experience: UX) ที่ดี เพื่อให้เกิดการ Conversion สูงสุด เช่น การซื้อสินค้าหรือการกรอกข้อมูลในฟอร์ม โดย SXO รวมการปรับปรุงทั้ง SEO และ UX เข้าด้วยกันเพื่อสร้างทั้งการเข้าชมที่มีคุณภาพและเพิ่มโอกาสในการแปลงผล (Conversions) เช่น การสมัครสมาชิก, การซื้อสินค้า, หรือการดาวน์โหลดเนื้อหา
ความสำคัญของ SXO
- เน้นประสบการณ์ผู้ใช้เป็นหลัก
SXO ให้ความสำคัญกับประสบการณ์ของผู้ใช้เมื่อเข้าชมเว็บไซต์ ไม่ใช่เพียงแค่การติดอันดับในเครื่องมือค้นหาเท่านั้น ผู้ใช้ควรมีประสบการณ์ที่ราบรื่นและสะดวกในการใช้งาน เช่น เว็บไซต์โหลดเร็ว, การออกแบบที่เข้าใจง่าย, และการแสดงผลที่ดีบนทุกอุปกรณ์ ทั้งหมดนี้ช่วยสร้างความพึงพอใจและทำให้ผู้ใช้ต้องการกลับมาเยี่ยมชมอีก
- เพิ่ม Conversion Rate
SXO ช่วยให้ผู้ใช้ที่เข้ามาผ่านการค้นหาทำสิ่งที่คุณต้องการได้ง่ายขึ้น เช่น การกรอกแบบฟอร์ม การซื้อสินค้า หรือการสมัครสมาชิก โดยไม่เพียงแค่ดึงดูดผู้เข้าชม แต่ยังทำให้ผู้เข้าชมมีแนวโน้มที่จะดำเนินการบนเว็บไซต์มากขึ้น
- สร้างความสมดุลระหว่าง SEO และ UX
ในขณะที่ SEO มุ่งเน้นที่การปรับปรุงเนื้อหาและโครงสร้างของเว็บไซต์เพื่อให้ติดอันดับสูงในผลการค้นหา SXO จะเพิ่มการใส่ใจ UX เข้าไปด้วย ซึ่งเป็นการทำให้ผู้ใช้ได้รับประสบการณ์ที่ดีตั้งแต่การค้นหาจนถึงการใช้งานเว็บไซต์ ผลที่ได้คือทั้งการเข้าชมที่มากขึ้นและผู้ใช้ที่มีความสุขมากขึ้น
- ลดอัตราการเด้งออก (Bounce Rate)
การปรับปรุง UX ให้ผู้ใช้มีความสะดวกสบายในการใช้งาน จะช่วยลดอัตราการเด้งออก ซึ่งเป็นหนึ่งในปัจจัยที่เครื่องมือค้นหาใช้ในการพิจารณาคุณภาพของเว็บไซต์ ยิ่งผู้ใช้ใช้เวลาบนเว็บไซต์นานเท่าไร ก็จะยิ่งส่งสัญญาณเชิงบวกต่อเครื่องมือค้นหา
- เพิ่มความเกี่ยวข้องและคุณภาพของเนื้อหา
SXO เน้นการสร้างเนื้อหาที่ไม่เพียงแต่มีคีย์เวิร์ดที่เกี่ยวข้อง (SEO) แต่ยังต้องให้ข้อมูลที่มีคุณค่าและตอบโจทย์ความต้องการของผู้ใช้ด้วย การทำให้เนื้อหาน่าสนใจและมีคุณภาพช่วยเพิ่มความพึงพอใจของผู้ใช้และทำให้เว็บไซต์มีความเกี่ยวข้องมากขึ้นกับคำค้นหา
- สร้างความไว้วางใจและความน่าเชื่อถือ
เมื่อผู้ใช้มีประสบการณ์ที่ดีบนเว็บไซต์ พวกเขาจะมีแนวโน้มที่จะไว้วางใจในแบรนด์หรือธุรกิจของคุณมากขึ้น ความน่าเชื่อถือเป็นสิ่งสำคัญในโลกออนไลน์ โดยเฉพาะเมื่อเว็บไซต์สามารถนำเสนอเนื้อหาและประสบการณ์ที่ดี
เครื่องมือที่ช่วยในการทำ SXO (Search Experience Optimization) นอกจากเครื่องมือ SEO ปกติแล้วยังมีเครื่องมือที่เน้นการวิเคราะห์ประสบการณ์ผู้ใช้และการเพิ่ม Conversion โดยเฉพาะ ตัวอย่างเช่น:
- Google Analytics
- ใช้ติดตามพฤติกรรมของผู้ใช้บนเว็บไซต์ เช่น อัตราการคลิก (CTR), เวลาที่ใช้บนเว็บไซต์ (Time on Site), Bounce Rate และ Conversion Rate เพื่อให้รู้ว่าผู้ใช้โต้ตอบกับเว็บไซต์อย่างไรและทำอย่างไรจึงจะทำให้ประสบการณ์การใช้งานดีขึ้น
- Hotjar
- เป็นเครื่องมือสำหรับวิเคราะห์พฤติกรรมของผู้ใช้ เช่น Heatmaps, Recordings, และแบบสอบถาม ซึ่งช่วยให้เห็นว่า ผู้ใช้คลิกหรือเลื่อนหน้าจอในส่วนไหนบ้าง เพื่อให้สามารถปรับปรุง UX ตามพฤติกรรมของพวกเขาได้
- Crazy Egg
- เครื่องมือที่ใช้สร้าง Heatmaps และ Scrollmaps เพื่อติดตามพฤติกรรมของผู้ใช้ ทำให้สามารถเข้าใจว่าผู้ใช้สนใจส่วนไหนของเว็บไซต์และออกแบบให้สอดคล้องกับความต้องการได้
- A/B Testing Tools (เช่น Optimizely, VWO)
- ใช้สำหรับการทดสอบ A/B Testing เพื่อเปรียบเทียบหน้าตาและฟังก์ชันการใช้งานต่างๆ ของเว็บไซต์ ว่าเวอร์ชันใดที่ช่วยเพิ่ม Conversion หรือให้ประสบการณ์ที่ดีขึ้นแก่ผู้ใช้
- PageSpeed Insights
- เป็นเครื่องมือของ Google ที่ช่วยวิเคราะห์ความเร็วในการโหลดเว็บไซต์ ซึ่งเป็นส่วนสำคัญของประสบการณ์ผู้ใช้ โดยเครื่องมือนี้จะบอกว่าคุณควรปรับปรุงอะไรเพื่อให้เว็บไซต์โหลดเร็วขึ้น
- Google Optimize
- เครื่องมือของ Google ที่ช่วยให้คุณสามารถทำการทดลองกับหน้าเว็บเพื่อดูว่าการเปลี่ยนแปลงใดจะช่วยเพิ่ม Conversion มากที่สุด
SXO เป็นการรวม SEO และ UX เข้าด้วยกัน โดยมีเป้าหมายไม่เพียงแค่การดึงดูดผู้เข้าชมผ่านเครื่องมือค้นหา แต่ยังมุ่งเน้นให้พวกเขาได้รับประสบการณ์ที่ดีและทำการแปลงผล (Conversion) บนเว็บไซต์ได้อย่างมีประสิทธิภาพ ถือเป็นแนวทางที่สำคัญในการเพิ่มทั้งปริมาณและคุณภาพของการเข้าชม พร้อมกับการสร้างความพึงพอใจให้กับผู้ใช้
สำหรับการพัฒนา Mobile Application โดยใช้เทคโนโลยี AI มีหลากหลายด้านที่สามารถนำมาใช้งานได้ มีตัวอย่างเทคโนโลยีดังต่อไปนี้
- Natural Language Processing (NLP) เป็นเทคโนโลยีการประมวลผลภาษาธรรมชาติที่ช่วยให้แอปพลิเคชันสามารถเข้าใจและตอบสนองต่อคำพูดหรือข้อความของผู้ใช้ได้ดีขึ้น เช่น การแชทบอท (Chatbot) การแปลภาษา การวิเคราะห์ความรู้สึกจากข้อความ เป็นต้น
- Computer Vision เป็นเทคโนโลยีที่ใช้ในการวิเคราะห์และประมวลผลภาพ เช่น การจดจำใบหน้า การตรวจจับวัตถุ การวิเคราะห์ภาพจากกล้องมือถือ สามารถนำมาใช้ในแอปพลิเคชันประเภทความปลอดภัย การช้อปปิ้ง หรือการทำ AR (Augmented Reality)
- Augmented Reality (AR) และ Virtual Reality (VR) เป็นเทคโนโลยีที่ใช้ในการสร้างประสบการณ์ที่ผสมผสานโลกดิจิทัลกับโลกจริง ในขณะที่ VR เป็นการสร้างโลกดิจิทัลเสมือนจริงทั้งหมด เทคโนโลยีเหล่านี้สามารถนำไปใช้ในเกม, การศึกษา, การช้อปปิ้ง, การท่องเที่ยว เป็นต้น
- Recommendation Systems เป็นเทคโนโลยีที่ใช้ในการแนะนำผลิตภัณฑ์หรือเนื้อหาตามพฤติกรรมหรือความชอบของผู้ใช้ เช่น แอปช้อปปิ้งหรือแอปดูหนังที่จะแนะนำสิ่งที่เหมาะสมตามการใช้งานของผู้ใช้
- Image Recognition เป็นเทคโนโลยีที่ใช้ในการจดจำและแยกแยะภาพต่าง ๆ เช่น การจดจำใบหน้า, การตรวจจับวัตถุ หรือการแยกประเภทของรูปภาพ สามารถนำไปใช้ในแอปพลิเคชันด้านความปลอดภัย, การศึกษา, และสุขภาพ
- Predictive Analytics เป็นเทคโนโลยีที่ใช้ AI ในการทำนายหรือคาดการณ์พฤติกรรมหรือแนวโน้มในอนาคต เช่น แอปการเงินที่คาดการณ์รายจ่าย หรือแอปสุขภาพที่ทำนายระดับสุขภาพ
- Speech Synthesis (Text-to-Speech) เป็นเทคโนโลยีที่แปลงข้อความให้กลายเป็นเสียงพูด สามารถนำมาใช้ในแอปพลิเคชันต่าง ๆ เช่น แอปสำหรับการอ่านหนังสือหรือเอกสาร แอปสำหรับคนพิการทางสายตา
- Sentiment Analysis เป็นเทคโนโลยีที่ใช้ AI ในการวิเคราะห์อารมณ์หรือความรู้สึกจากข้อความของผู้ใช้ ช่วยให้แอปพลิเคชันสามารถเข้าใจอารมณ์ของผู้ใช้ได้ เช่น ในแอปพลิเคชันบริการลูกค้า หรือโซเชียลมีเดีย
- Voice Assistants เป็นเทคโนโลยีที่สร้างแอปที่รองรับผู้ช่วยเสียง (Voice Assistant) เช่น การสั่งงานด้วยเสียงผ่าน Siri, Google Assistant หรือ Alexa
- Biometric Authentication เป็นเทคโนโลยีที่ใช้ AI ในการจดจำลายนิ้วมือ, ใบหน้า หรือแม้กระทั่งการจดจำเสียง เพื่อใช้ในการยืนยันตัวตนของผู้ใช้ แอปพลิเคชันที่ใช้เทคโนโลยีนี้จะช่วยเพิ่มความปลอดภัย เช่น แอปธนาคาร, การเข้าสู่ระบบต่าง ๆ
Data Integration Tools เป็นเครื่องมือที่ช่วยในการรวบรวม จัดการ และผสานข้อมูลจากหลายแหล่งที่มา เช่น ฐานข้อมูล ระบบคลังข้อมูล แอปพลิเคชัน หรือไฟล์รูปแบบต่างๆ ให้กลายเป็นข้อมูลชุดเดียวที่เชื่อมโยงกันอย่างมีประสิทธิภาพ เครื่องมือเหล่านี้มีบทบาทสำคัญในองค์กรที่ต้องจัดการข้อมูลจากหลายระบบ เพื่อให้สามารถนำไปใช้ประโยชน์ในการวิเคราะห์ การทำรายงาน หรือการตัดสินใจได้
ประเภท Data Integration Tools
- On-Premise Data Integration Tools เป็นเครื่องมือที่ติดตั้งและทำงานในโครงสร้างพื้นฐานขององค์กรเอง โดยไม่ต้องพึ่งพาโซลูชันคลาวด์ ข้อมูลทั้งหมดจะถูกจัดการภายในองค์กร ทำให้มีการควบคุมข้อมูลที่เข้มงวดและลดความเสี่ยงในการรั่วไหลของข้อมูล เหมาะสำหรับองค์กรที่มีการรักษาความปลอดภัยข้อมูลสูง ตัวอย่างเครื่องมือ: Microsoft SQL Server Integration Services (SSIS) Informatica PowerCenter และ IBM InfoSphere DataStage
- Cloud-Based Data Integration Tools เป็นเครื่องมือที่ทำงานบนระบบคลาวด์ โดยไม่จำเป็นต้องติดตั้งหรือจัดการโครงสร้างพื้นฐานเอง การผสานข้อมูลทำได้ง่ายและรวดเร็วผ่านการเชื่อมต่อกับระบบคลาวด์ต่าง ๆ เช่น SaaS, IaaS, หรือ PaaS เหมาะสำหรับองค์กรที่ใช้แอปพลิเคชันและบริการต่าง ๆ บนคลาวด์ และไม่ต้องการลงทุนในโครงสร้างพื้นฐานภายใน ตัวอย่างเครื่องมือ: Talend Cloud Integration Dell Boomi และ Zapier
- Hybrid Data Integration Tools เป็นเครื่องมือที่รองรับทั้งการทำงานในระบบ on-premise และ cloud-based เหมาะสำหรับองค์กรที่ต้องการผสานข้อมูลจากทั้งระบบภายในและภายนอก (คลาวด์) เครื่องมือประเภทนี้ช่วยให้การจัดการข้อมูลข้ามแพลตฟอร์มเป็นไปอย่างมีประสิทธิภาพ เหมาะสำหรับองค์กรที่ใช้ทั้งระบบ on-premise และ cloud ในการจัดเก็บและประมวลผลข้อมูล ตัวอย่างเครื่องมือ: Informatica Intelligent Cloud Services Microsoft Azure Data Factory และ Talend Data Fabric
- Open Source Data Integration Tools เป็นเครื่องมือที่ให้บริการฟรีหรือมีค่าใช้จ่ายน้อย โดยมีความยืดหยุ่นสูง เนื่องจากสามารถเข้าถึงและปรับแต่งซอร์สโค้ดได้ เหมาะสำหรับองค์กรที่ต้องการควบคุมการพัฒนาระบบเองหรือมีงบประมาณจำกัด เหมาะสำหรับองค์กรที่ต้องการโซลูชันที่ปรับแต่งได้เอง ต้องการประหยัดค่าใช้จ่ายในการซื้อซอฟต์แวร์เชิงพาณิชย์ นักพัฒนาที่มีความสามารถในการปรับแต่งซอฟต์แวร์ตามความต้องการขององค์กร ตัวอย่างเครื่องมือ: Talend Open Studio Apache Nifi และ Pentaho Data Integration (PDI)
การเลือกประเภทของ Data Integration Tools ขึ้นอยู่กับความต้องการขององค์กร เช่น ความต้องการด้านความปลอดภัย การควบคุมข้อมูล ขนาดของข้อมูล และสภาพแวดล้อมการทำงาน ทั้งนี้ On-Premise Tools เหมาะกับองค์กรที่ต้องการควบคุมข้อมูลทั้งหมด ในขณะที่ Cloud-Based Tools เหมาะกับองค์กรที่ต้องการความยืดหยุ่น และ Open Source Tools เหมาะสำหรับองค์กรที่ต้องการปรับแต่งโซลูชัน
Data Lakehouse เป็นแนวคิดที่รวมคุณสมบัติของ Data Lake และ Data Warehouse เข้าไว้ด้วยกัน เพื่อใช้ประโยชน์จากจุดเด่นของทั้งสองแนวทางในการจัดเก็บและวิเคราะห์ข้อมูล โดยการรวมความสามารถของการจัดเก็บข้อมูลดิบแบบยืดหยุ่นของ Data Lake เข้ากับประสิทธิภาพในการวิเคราะห์ข้อมูลเชิงโครงสร้างของ Data Warehouse
หลักการจัดทำ Data Lakehouse มีดังนี้:
- Unified Data Storage
- Data Lakehouse สามารถจัดเก็บทั้งข้อมูลดิบ (Raw Data) แบบเดียวกับ Data Lake และข้อมูลที่ผ่านการจัดโครงสร้างแล้ว (Structured Data) เหมือนกับ Data Warehouse ได้ในระบบเดียว
- ข้อมูลที่เก็บสามารถมีได้ทั้งข้อมูลที่ไม่มีโครงสร้าง เช่น ไฟล์เสียง, วิดีโอ หรือข้อความ และข้อมูลที่มีโครงสร้าง เช่น ตารางข้อมูลหรือฐานข้อมูลเชิงสัมพันธ์ (Relational Databases)
- การรองรับการประมวลผลแบบ Schema-on-Read และ Schema-on-Write
- ใน Data Lakehouse ข้อมูลสามารถถูกประมวลผลทั้งในแบบ Schema-on-Read (การสร้างโครงสร้างข้อมูลเมื่อดึงข้อมูลไปใช้) และ Schema-on-Write (การกำหนดโครงสร้างข้อมูลล่วงหน้าก่อนนำเข้าระบบ) ขึ้นอยู่กับความต้องการในการวิเคราะห์
- ข้อมูลดิบสามารถถูกเก็บโดยไม่ต้องแปลงโครงสร้างล่วงหน้า และจะถูกจัดโครงสร้างเมื่อมีความจำเป็น เช่น การนำไปใช้ในการวิเคราะห์เชิงลึก
- Metadata Management & Indexing
- Data Lakehouse ต้องมีการจัดการเมตาดาต้า (Metadata) ที่มีประสิทธิภาพ เพื่อช่วยให้สามารถค้นหาข้อมูลได้อย่างรวดเร็วและง่ายดาย
- การกำหนดดัชนี (Indexing) ของข้อมูลทำให้สามารถเข้าถึงและประมวลผลข้อมูลได้เร็วขึ้น เมื่อเทียบกับการค้นหาข้อมูลจาก Data Lake
- Real-time and Batch Processing
- Data Lakehouse รองรับการประมวลผลข้อมูลทั้งแบบเรียลไทม์ (Real-time) และแบบชุดข้อมูลขนาดใหญ่ (Batch Processing) ทำให้สามารถใช้งานได้หลากหลาย ทั้งการวิเคราะห์ข้อมูลที่เกิดขึ้นแบบต่อเนื่อง (Streaming Data) และการประมวลผลข้อมูลที่สะสมมาแล้ว
- การรวมความสามารถนี้ทำให้ Data Lakehouse มีความยืดหยุ่นมากกว่าระบบที่รองรับเพียงหนึ่งวิธีการประมวลผล
- Advanced Analytics
- Data Lakehouse ช่วยให้สามารถทำ Business Intelligence (BI), Data Science, Machine Learning (ML) และ AI ได้ในแพลตฟอร์มเดียว โดยมีการใช้ข้อมูลจากทั้งข้อมูลดิบและข้อมูลที่จัดโครงสร้างแล้ว
- นักวิเคราะห์ข้อมูลสามารถใช้งานเครื่องมือวิเคราะห์ข้อมูลจากทั้งสองประเภทข้อมูลได้อย่างไร้รอยต่อ ช่วยให้ได้ผลลัพธ์ที่มีประสิทธิภาพ
- Multi-tiered Data Management
- Data Lakehouse มีการจัดการข้อมูลในหลายระดับ เช่น ข้อมูลที่ถูกใช้งานบ่อยจะถูกเก็บในที่ที่เข้าถึงได้รวดเร็ว (Hot Storage) ในขณะที่ข้อมูลที่ใช้งานน้อยจะถูกเก็บในพื้นที่ที่มีต้นทุนต่ำกว่า (Cold Storage)
- การแบ่งชั้นข้อมูลตามการใช้งานช่วยให้สามารถจัดการต้นทุนในการเก็บข้อมูลได้อย่างมีประสิทธิภาพ โดยไม่สูญเสียความสามารถในการเข้าถึงข้อมูล
- Data Access Optimization
- เพื่อให้การเข้าถึงข้อมูลทำได้รวดเร็วขึ้น ระบบ Data Lakehouse มีการใช้เทคโนโลยีเพิ่มประสิทธิภาพ เช่น การเก็บข้อมูลในรูปแบบ Columnar Format หรือการบีบอัดข้อมูล
- ยังสามารถใช้เทคนิคการสร้างพาร์ทิชัน (Partitioning) และการทำคลังข้อมูลแคช (Caching) เพื่อเพิ่มประสิทธิภาพในการสืบค้นข้อมูลได้
- Security & Privacy Control
- การรักษาความปลอดภัยข้อมูลใน Data Lakehouse เป็นสิ่งสำคัญ จำเป็นต้องมีการกำหนดสิทธิ์การเข้าถึงตามบทบาทผู้ใช้ (Role-Based Access Control: RBAC) รวมถึงการเข้ารหัสข้อมูล (Encryption) เพื่อปกป้องข้อมูลสำคัญ
- ต้องมีการจัดการความเป็นส่วนตัวตามข้อกำหนดของกฎหมายและมาตรฐานสากล เช่น GDPR เพื่อรักษาความปลอดภัยข้อมูลของผู้ใช้งาน
- Integration with Various Tools and Technologies
- Data Lakehouse รองรับการทำงานร่วมกับเครื่องมือหลากหลาย เช่น เครื่องมือ ETL, การวิเคราะห์ Big Data, เครื่องมือ BI, Data Science Tools และ Machine Learning Frameworks เพื่อให้สามารถวิเคราะห์ข้อมูลได้ทุกมิติ
- ระบบต้องมี API หรืออินเตอร์เฟซที่รองรับการเชื่อมต่อกับแพลตฟอร์มและเทคโนโลยีต่างๆ อย่างราบรื่น
- Maintenance & Optimization
- ต้องมีการดูแลรักษาระบบ Data Lakehouse ให้ทันสมัยอยู่เสมอ เช่น การเพิ่มประสิทธิภาพการประมวลผลข้อมูล, การปรับปรุงดัชนี และการจัดการพื้นที่เก็บข้อมูลอย่างมีประสิทธิภาพ
- การตรวจสอบและปรับปรุงข้อมูลอย่างต่อเนื่องช่วยให้สามารถคงประสิทธิภาพในการสืบค้นและวิเคราะห์ข้อมูลได้
Data Lakehouse เป็นโซลูชันที่ช่วยแก้ไขปัญหาของ Data Lake ในเรื่องประสิทธิภาพการสืบค้นข้อมูล และปัญหาของ Data Warehouse ในเรื่องความยืดหยุ่นในการจัดเก็บข้อมูล จึงเป็นแพลตฟอร์มที่เหมาะสมสำหรับการบริหารจัดการข้อมูลขนาดใหญ่ในยุคที่ข้อมูลมีความหลากหลายและซับซ้อน







