
‘สืบค้นข้อมูล สร้างเอกสารราชการ ถอดเทปภาษาไทย’ ง่าย ๆ ด้วย ‘Pathumma LLM’

Pathumma LLM (ปทุมมา แอลแอลเอ็ม) คือ Large Language Model (LLM) สัญชาติไทย ที่ผ่านการฝึกฝนจากข้อมูลภาษาไทยจำนวนมหาศาล เพื่อให้มีความสามารถเฉพาะทางโดยเฉพาะทักษะด้านภาษาและการสื่อสารแบบมนุษย์ ผู้วิจัยตั้งเป้าหมายการพัฒนาว่าจะทำให้ Pathumma LLM เป็น AI ที่เชี่ยวชาญทั้งภาษา ข้อมูล และบริบทประเทศไทย ซึ่งจะเป็นกำลังสำคัญที่ช่วยสนับสนุนการขับเคลื่อนระบบบริการ AI ของประเทศไทยในอนาคต
กระทรวงการอุดมศึกษา วิทยาศาสตร์ วิจัยและนวัตกรรม (อว.) โดยศูนย์เทคโนโลยีอิเล็กทรอนิกส์และคอมพิวเตอร์แห่งชาติ (เนคเทค) สำนักงานพัฒนาวิทยาศาสตร์และเทคโนโลยีแห่งชาติ (สวทช.) ร่วมกับคณะทำงานจาก AI Engineer ซีซัน 4 เดินหน้าพัฒนา Pathumma LLM ต่อเนื่องหลังเปิดให้สาธารณะทดลองใช้เวอร์ชัน 1.0.0 ในรูปแบบ Generative AI หรือเอไอแบบรู้สร้าง เมื่อช่วงปลายปี 2567 และได้เปิดตัวเทคโนโลยีเด่นอีก 3 เทคโนโลยีที่จะช่วยลดเวลาการทำงาน ‘สืบค้นข้อมูล สร้างเอกสารราชการ และถอดเทป’ ให้เหลือหลักวินาที เพื่อให้คนทำงานได้ใช้เวลาคิดวิเคราะห์และสร้างสรรค์งานให้มีคุณภาพมากยิ่งขึ้น ในงานประชุมวิชาการประจำปี สวทช. ครั้งที่ 20 (NAC 2025) ที่จัดขึ้นเมื่อวันที่ 26-28 มีนาคมที่ผ่านมา
เปิดตัวแล้ว 3 เทคฯ AI เด่น สลัดทิ้งความน่าเบื่อในการทำงาน

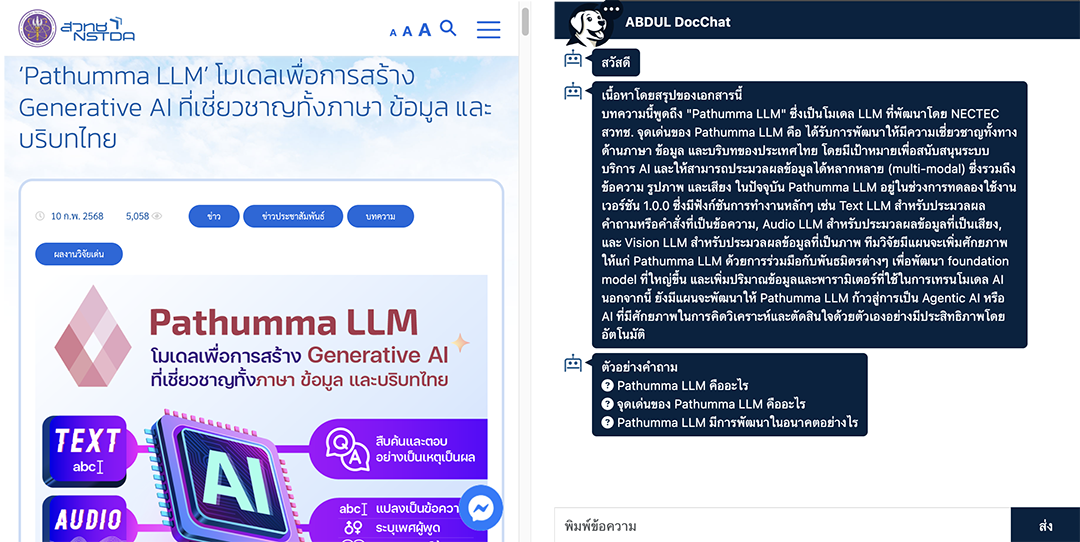
ดร.ศราวุธ คงยัง นักวิจัยกลุ่มนวัตกรรมการผลิตยั่งยืน สวทช. เล่าว่า เทคโนโลยีแรก คือ DocChat (ด็อกแชต) ระบบสืบค้นและตอบคำถามข้อมูลจากข้อความ เว็บไซต์ (ใส่ URL) และไฟล์ข้อความ (อัปโหลดไฟล์ PDF) เหมาะกับงานสืบค้นข้อมูลจากแหล่งที่มีอยู่ โดยเฉพาะหน่วยงานที่มีข้อมูลปริมาณมาก เช่น รัฐสภา หน่วยงานวิจัย เมื่อผู้ใช้งานนำข้อมูลเข้าสู่ระบบ AI จะสรุปภาพรวมของข้อมูล พร้อมตั้งตัวอย่างคำถามที่ผู้ใช้งานอาจสนใจเกี่ยวกับข้อมูลชุดนั้นให้โดยอัตโนมัติภายในเวลาหลักวินาที ผู้ใช้งานสามารถคลิกเพื่อเลือกถามคำถามนั้น ๆ หรือตั้งคำถามอื่น ๆ เพื่อให้ AI ช่วยสืบค้นข้อมูลและตอบคำถามอ้างอิงจากข้อมูลนั้น ๆ ได้ จุดเด่นของเทคโนโลยีนี้คือแม้คำที่ใช้ในการสืบค้นจะไม่ตรงกับคำที่มีอยู่ภายในเอกสาร AI ก็สามารถทำความเข้าใจและค้นหาคำที่มีความหมายใกล้เคียงกันให้แทนได้ ทำให้การสืบค้นข้อมูลทำได้ง่ายและรวดเร็ว ผู้ที่สนใจทดลองใช้งานได้ที่ https://docchat.abdul.in.th/

“เทคโนโลยีที่สอง DocGen (ด็อกเจน) คือ ระบบช่วยสร้างเอกสารตามรูปแบบขององค์กร เหมาะกับการช่วยร่างเอกสารที่มีรูปแบบชัดเจน และต้องใช้เวลาในการเรียบเรียงนาน เช่น TOR (Terms of Reference) หรือขอบเขตของโครงการ, รายงานการประชุม การใช้งานทำได้ง่ายเพียงผู้ใช้งานใส่ข้อมูลตั้งต้นและประเภทของเอกสารที่ต้องการให้ AI ช่วยร่าง AI จะร่างเอกสารให้ทันทีภายในเวลาหลักวินาที โดยผู้ใช้สามารถแก้ไข ปรับปรุง และดาวน์โหลดเป็นไฟล์เอกสารได้ ผู้ที่สนใจทดลองใช้งานได้ที่ https://docgen.abdul.in.th/


นอกจากงานประเภทสืบค้นข้อมูลและร่างเอกสารที่ต้องใช้เวลาและพลังในการทำงานสูงแล้ว อีกหนึ่งงานที่ใช้เวลาทำงานมาก จนหลายคนเลือกใช้เงินแก้ปัญหา คือ การถอดเทปหรือการถอดข้อความจากไฟล์เสียงหรือวิดีโอ ซึ่งโดยปกติเทปความยาวประมาณ 1 ชั่วโมง จะใช้เวลาในการถอดนาน 3-5 ชั่วโมง ขึ้นอยู่กับความเชี่ยวชาญของผู้ถอดเทป
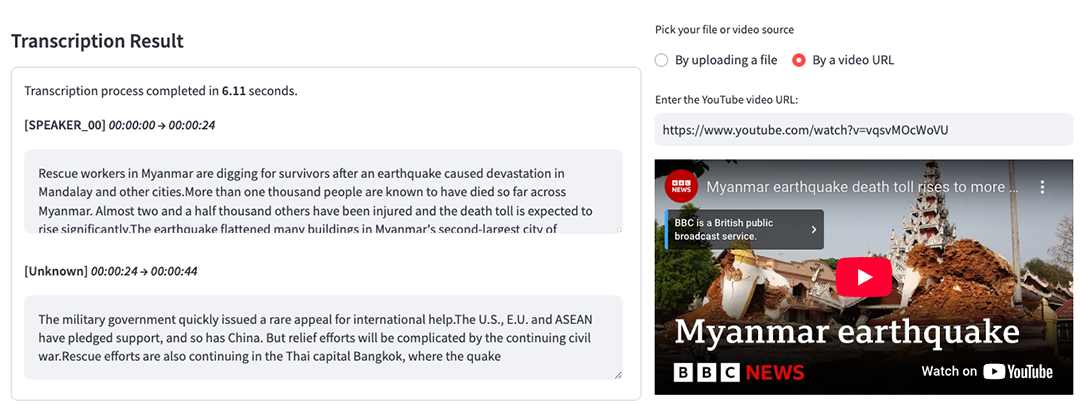
ดร.ศราวุธ เล่าต่อว่า เทคโนโลยีเด่นสุดท้ายที่เปิดตัวในคราวนี้ คือ PartiiNote เว็บแอปพลิเคชันสำหรับถอดเทปที่ถอดได้ 3 ภาษา คือ ไทย อังกฤษ และจีน นอกจากนี้ยังแปลจากภาษาอังกฤษให้เป็นภาษาไทยได้ด้วย (กรณีภาษาจีน สามารถเลือกแปลเป็นภาษาอังกฤษก่อนแล้วแปลเป็นภาษาไทยต่อได้) PartiiNote รองรับทั้งการถอดเทปจากไฟล์ MP3, MP4, WAV และ MPEG4 ขนาดไฟล์ไม่เกิน 200 MB และคลิปวิดีโอจาก YouTube ความยาวสูงสุด 1 ชั่วโมง ซึ่งโดยทั่วไปจะใช้เวลาในการถอดหลักวินาที โดยหากเสียงมีความชัดเจน ความแม่นยำในการถอดเทปจะมากกว่าร้อยละ 95 (กรณีมีผู้ใช้บริการ ณ ขณะนั้นมากอาจใช้เวลาในการประมวลผลมากขึ้น เนื่องด้วยข้อจำกัดด้านทรัพยากร) ผู้ที่สนใจทดลองใช้งานได้ที่ https://note.abdul.in.th/

‘Pathumma LLM’ เตรียมฉลาดขึ้นกว่าเดิมหลายเท่าตัว
ดร.ศราวุธ เล่าว่า ปัจจุบัน Pathumma LLM เรียนรู้ข้อมูลภาษาไทยแล้วมากกว่าสองหมื่นล้านโทเคน ซึ่งถือว่าเป็นข้อมูลที่น้อยมากเมื่อเทียบกับ Generative AI ระดับโลกที่เปิดให้บริการอยู่ในปัจจุบัน เช่น GPT-4 ซึ่งเรียนรู้ข้อมูลแล้วมากกว่าหลายล้านล้านโทเคน อย่างไรก็ตามทีมวิจัยกำลังดำเนินงานความร่วมมือกับพันธมิตรทั้งภาครัฐและเอกชนไทยในการพัฒนา foundation model หรือโมเดลพื้นฐานสำหรับประเทศไทยที่มีขนาดใหญ่ขึ้น เพื่อเพิ่มศักยภาพในการรองรับปริมาณข้อมูลและพารามิเตอร์ที่ใช้ในการเทรนโมเดล โดยเมื่อพัฒนาแล้วเสร็จจะสามารถนำโมเดลพื้นฐานที่พัฒนานี้มาใช้เพิ่มศักยภาพให้แก่ Pathumma LLM ได้ คาดว่าในอนาคตอันใกล้ Pathumma LLM จะได้เรียนรู้ข้อมูลภาษาไทยมากกว่าแสนล้านโทเคน หรือมากกว่าข้อมูลภาษาไทยที่ระบบ Generative AI ของชาติอื่นจะเข้าถึงการเรียนรู้ได้ ซึ่งการดำเนินงานข้างต้นนี้จะสำเร็จได้ด้วยดีหากได้รับการอนุเคราะห์เอกสารและสื่อการเรียนรู้ภาษาไทย และการสนับสนุนทุนทรัพย์ในการใช้งานระบบโครงสร้างพื้นฐานที่จำเป็นต่อการพัฒนา AI จากทั้งภาครัฐและเอกชนไทย

แม้ปัจจุบัน Pathumma LLM จะยังเป็นเวอร์ชัน 1.0.0 หรือยังคงอยู่ในขั้นตอนการวิจัยและพัฒนา แต่ทีมวิจัยได้เลือกเปิดให้ผู้ที่สนใจเข้าทดลองใช้งานและดาวน์โหลดโมเดลไปพัฒนาต่อแล้ว โดยเป้าหมายของการเปิดให้ใช้งานเทคโนโลยี คือ การส่งเสริมให้ภาครัฐและเอกชนไทยเข้าถึงการใช้งาน AI ในการขับเคลื่อนองค์กรได้ทันการเปลี่ยนแปลงของโลก
ดร.ศราวุธ เล่าต่อว่า การใช้งาน Pathumma LLM, DocChat, DocGen และ PartiiNote แบบส่วนบุคคลผู้ที่สนใจสามารถเข้าใช้งานในรูปเว็บแอปพลิเคชันได้ผ่านทั้งคอมพิวเตอร์ สมาร์ตโฟน หรือแท็บเล็ตทั่วไป แต่สำหรับหน่วยงานที่สนใจนำโมเดล Pathumma LLM ไปพัฒนาต่อเพื่อใช้งานภายในองค์กรหรือพัฒนาเป็นระบบบริการของตัวเอง แต่ยังขาดความพร้อมด้านทรัพยากรในการประมวลผล เช่น GPU (Graphics Processing Unit) ประสิทธิภาพสูง อาจเลือกใช้บริการระบบ private cloud ซึ่งเป็นระบบคลาวด์ส่วนบุคคลหรือใช้งานเฉพาะภายในองค์กร จากผู้ให้บริการไทยหรือต่างประเทศเพื่อลดการลงทุนด้านโครงสร้างพื้นฐาน และหากต้องการใช้บริการด้านการพัฒนาระบบ Generative AI ขององค์กร ติดต่อขอใช้บริการด้านการวิจัยและพัฒนาได้ที่เนคเทค สวทช.
ผู้ที่สนใจเทคโนโลยี Pathumma LLM, DocChat, DocGen และ PartiiNote เข้าใช้งานทั้งรูปแบบ APP, API, open model โดยไม่ต้องเสียค่าใช้จ่ายได้ที่ https://aiforthai.in.th/pathumma-llm/ และติดต่อสอบถามรายละเอียดเพิ่มเติมเกี่ยวกับ Pathumma LLM ได้ที่ sarawoot.kon@nstda.or.th
บทความที่เกี่ยวข้อง : ‘Pathumma LLM’ โมเดลเพื่อการสร้าง Generative AI ที่เชี่ยวชาญทั้งภาษา ข้อมูล และบริบทไทย
เรียบเรียงโดย ภัทรา สัปปินันทน์ ฝ่ายสร้างสรรค์สื่อและผลิตภัณฑ์ สวทช.
อาร์ตเวิร์กโดย ภัทรา สัปปินันทน์
คลิปสั้นโดย ภัทรา สัปปินันทน์ และอัครวุฒิ ตู้วชิรกุล ฝ่ายประชาสัมพันธ์ สวทช.
ภาพประกอบโดย ภัทรา สัปปินันทน์, เนคเทค และจาก Adobe Stock








